EvoRepo - State of the art
Technical report
I. Introduction
The following document describes the EvoRepo project, its general purpose and its complete technical specifications.
I.1. Description
EvoRepo is a web application with the purpose of providing a open linked data endpoint for details regarding vulnerabilites and various problems found in GitHub Open Source projects. It servers not only as a tracker for various old problems, but also offers the possibility to find new possible problems, with a specific degree of certainty, thanks to the backend website and source code scanners.
As a general rule, EvoRepo will use current free data from various sources (ExploitDB, cve.mitre.org etc) and a internal mapping of all the gathered data to be able to output linked data with a relevant meaning.
II. Project architecture
II.1. Overview
EvoRepo is a project which aims to analize as many GitHub code deposits as possible. Because of the vast amount of data that needs to be processed, our project was built with modularization and distributed cluster execution in mind. But even in this organization form, the project has three main components:
- EvoRepo core: holds the project controller and the clusters with each worker
- EvoRepo web: holds the web server, the database and the caching system
- EvoRepo IaaS: a infrastructure in which all the instances of the project get emulated
II.2. EvoRepo core
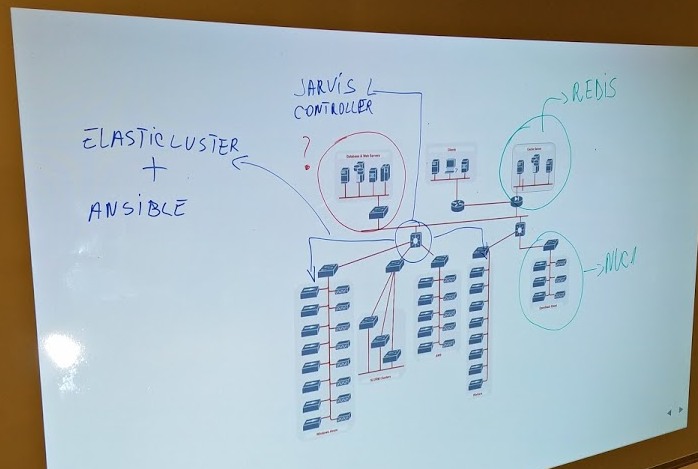
Because of the volume of data waiting to be processed and adnotated, we decided to tackle a architecture based on microservices. Every functionality within our project will be incapsulated in a microservice, offering us the chance to actually built it as a daemon on the system or include it in a Docker container.
All of these microservices are distributed within a cluster through the help of a framework we developed called Jarvis.
The Jarvis framework will take care of the configuration of the workspace and also of the distribution of every microservice necesary for a running, operational project, in the created workspace.
For the configuration of the clusters, we ended up choosing the famous "University of Zurich" developed Elasticluster. With the help of their project and Ansible playbooks, we are able to configure a batch of clusters using Windows Azure, OpenStack, AWS or Google Cloud Engine services.
II.2. EvoRepo web
EvoRepo Web is the only component of the project that is exposed to the outside world, to human or machine users. The main node of this component is the web server which will expose the human-friendly interface and also the public REST API containing the SPARQL endpoint.
The technologies chose for this component are the following:
- Web server: nginx
- Database server: Virtuoso Open-Source Edition - also used for the Sparql endpoint
- Caching server: Redis
II.3. EvoRepo IaaS
Because of the fact that the daemons will take care of the dynamic analysis of the incoming data, we need a safe and controlled environment to run / analyse the incoming data.
This component leaves to the daemon's disposal the workspace / environment in which anything can be controllably executed.
III.Content analysis
To be able to detect the eventual problems that can occur in a open-source project, for each modification a user submits into the project, we will run a series of processing functions based on the type of project and the used internal technologies.
If the system detects a new modification (a commit in the project), it will program a series of agents to take a look at the integrity of the project. Each of the available agents in the application hits one of two categories: static analysis agents and dynamic analysis agents.
III.1. Analiză statică
In sync with the type of technologies used for the project, the modification will be programmed for one or more daemons available.
One actual example could be a fictional Project X, in which the technologies used inside the project are the following:
{
"C": 76,
"Python": 7877
}
Then, the commit that actually adds the modification can pe programmed for a static analysis with the "pylint" daemon:
{
"name": "pylint",
"language": "python",
"safety": "80",
"url": "/v.1/daemon/pylint"
}
A daemon for static analysis will check if in the modifications introduced we could find security problems or other issues that jeopardize the integrity of the project. In the case of a actual found problem, the daemon will directly communicate its findings to a supervizor which will add the data in the database so that the /analysis API can output it.
III.2. Dynamic analysis
Because multiple types of vulnerabilities can not be found with static analysis, we need a tool at a greater level. A series of daemons could analyse the modifications on the project dynamically and asses the impact the provide upon the integrity and the security of the application.
For a dynamic analysis, the time and resources needed for processing a certain modification are significantly bigger that the static approach, because of the need to emulate and run the project in a controlled environment and the actual phase of interacting with the deployed project.
IV. API
The application API serves one purpose: to expose the gathered information about a project and its problems in a linked data way.
IV.1. Structure
The first step is the structure. It was designed to a minimum to be able to simplify the data we can offer.
/project
- This will output data collected about a project.
- Data outputted:
- Name
- Contributors to the project that link to a certain problem
- URL
- GitHub repos
- Technologies used
- Vulnerabilities - a reference to analyses that provide actual problems
/contributor
- This will output data relevant to a certain contributor
- Data outputted:
- Name
- GitHub Account
- Project contributed to that have problems.
/analysis
- This will output data for a specific analysis made by a daemon.
- Data outputted:
- Internal ID
- Daemon (which one)
- Safety - a procentage of certainty
- Result - the result conclusion of the analysis
- Project - a reference to the project
- Commit - the modification that triggered it all
/daemon
- This will output data about a specific processing daemon
- This endpoint will not offer linked data
/result_type
- This will output data about the specific problem found in the project
/sparql
- This endpoint offers the classic sparql endpoint features
IV.2. Internal Workflow
The workflow is the following: A daemon analyses a modification in the project (added as a commit). Based on what it finds, if something relevant is to be said about that specific modification, the data is send to a supervizor that adds it to the database.
The API endpoint was structured so that the available information comes with a degree of certainty in direct contact to its validity. For example, for a specific analysis on MySQL injection opportunities, the daemon could find a possible way in, but through a regex match on the static file.
This find, although it could be relevant, represents a statement with a certain degree of risc. To solve this issue, we introduced a parameter that will hold a procentual value that will be used to state the certainty with which the statement was made. For the previous example, a good procentual value would be 20-30%.
IV.3. Linked data
The data offered by each of the endpoints will be linked to the common knowledge concept already available and with a custom RDF concept base designed from the ground up for our application. This is necesarry because the data we offer has multiple meanings and a complete description is in order.
V. Interface
V.1. Design
The interface will offer a structured view of the linked data the API provides. It will keep simple view of the data, providing also straight to the point statistics of the evolution of the project.

V.2. Implementation
Technology wise, we chose to main UI frameworks to aid us:
- React.js
- Backbone.js
React.js will help us build our frontend from the UI view components perspective. It is really easy to use and lets us reuse components, linking them to other data sources. Also, React lets us update our interface in real time very easily by only modifying data in the model layer of the application.
To be able to link the React.js components to our API, we will use Backbone.js to create models that keep themselves up-to-date with the data in the API.